


Radical Approaches to Healthcare: Our Thesis in Computational Biology
Over the last year we at Redpoint have been building a thesis around the opportunity to improve, streamline, and accelerate healthcare…

Over the last year we at Redpoint have been building a thesis around the opportunity to improve, streamline, and accelerate healthcare processes and treatment by leveraging artificial intelligence.
As we began to dive into the potential for artificial intelligence and machine learning to transform various industries by leveraging data and computation, healthcare was a clear application with high and growing spend. According to the Centers for Medicare & Medicaid Services (CMS), it accounts for over $3 trillion of spend in the US alone.
What is computational biology?
As defined by Nature, “computational biology and bioinformatics is an interdisciplinary field that develops and applies computational methods to analyze large collections of biological data, such as genetic sequences, cell populations or protein samples, to make new predictions or discover new biology. The computational methods used include analytical methods, mathematical modelling and simulation.”
We have seen several large areas of commercial opportunity. For example, we have seen companies leveraging computation to drive improvements in target identification for drug discovery or to more effectively diagnose diseases by analyzing cell-free DNA or scans.
Why now?
Beyond the overall market size and the opportunity in sub-segments like pharma R&D or insurance reimbursements, several factors have converged to make this the right time for widescale disruption in the industry.
Advancements in machine learning techniques
As we have discussed previously, machine learning capabilities have been advancing rapidly, so that areas like computer vision and deep learning can now be used for highly complex problems. Of course, broader technology advances in cloud computing, the proliferation of data, and infrastructure improvements for storing and processing this data have advanced progress as well.
Crisis moment in healthcare
According to CMS, health spending is projected to grow 1.2% faster than GDP per year over the 2016–25 period. However, according to The Commonwealth Fund, ironically, despite spending more on health care, Americans had poorer health outcomes than other high-income countries.
A study published in Nature illustrates how the amount of R&D spend per drug that is approved by the FDA has been increasing rapidly over the last 50 years. Each new drug now costs on average more than a billion dollars to develop. To address challenges in development, in 2016 pharmaceutical companies spent $52B acquiring drug assets across 923 transactions to build robust development pipelines.

Amazing founders
Lastly, we continue to consistently meet incredibly talented and passionate founders that are leveraging computational biology to disrupt various segments within healthcare. They are a mix of industry veterans and high caliber scientists that are on a mission to improve access and care.
What applications are ripe for disruption?
We have come across companies addressing each of the applications below. At times, a company’s business model does not fit clearly in one of these segments, but overlaps across more than one. In these cases, I have done my best to classify these companies according to their primary focus area.
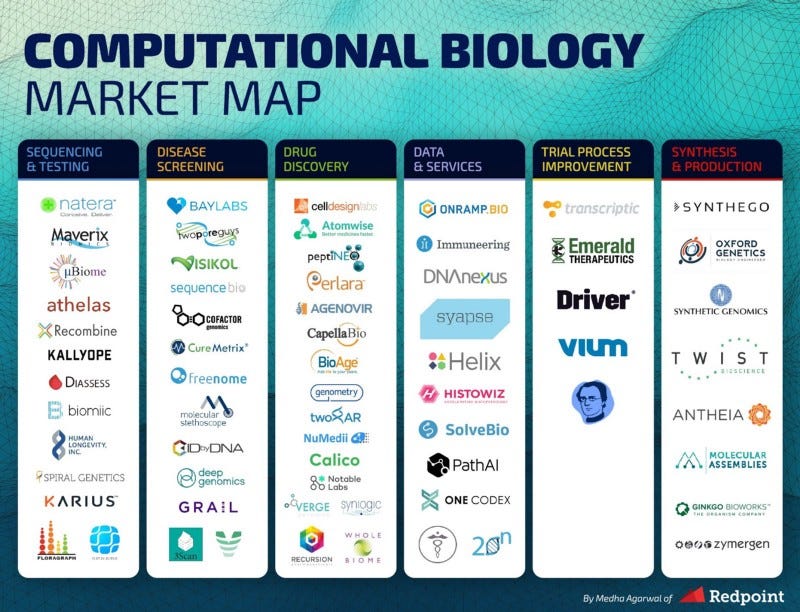
Sequencing & testing
Companies in this segment sequence the genome or test our microbiome, cell counts, and other indicators. The use cases vary from building a genetic and phenotypic database, to screening for disease, to improving the optimal mix of bacteria in the gut. Moreover, the process also varies, from using computer vision to detect and differentiate between cell types, to analyzing the mix of gut bacteria, to processing DNA rapidly.
Disease screening
Machine learning methods can be used to diagnose diseases earlier and more effectively. Either by leveraging computer vision to detect abnormalities in traditional scans or by analyzing trends and correlations in emerging tests like cell-free DNA or metabolomics, clinicians can leverage these tools to reduce misdiagnoses as well as to identify any issues earlier, as these methods can pick up fainter, earlier signs of disease before a human. In addition, because the program continues to learn over time as it gets feedback on the system, it can continue to learn from humans and to digest the constant flow of new studies that would be impossible for a single doctor to keep up with or to retain.
Drug Discovery
Computational biology has the potential to accelerate discovery processes and reduce false positives. At the most basic level, by finding patterns and running simulations via software, researchers can reduce the search space of testing for specific drug targets or potential compound profiles. Further, some companies are turning traditional R&D processes on their head by starting with the data, and mining it for insights instead of starting with a hypothesis and testing it.
Despite these advances, software does not eliminate the need to run experiments on a wet bench; biology is complicated and difficult to predict with complete accuracy so it will continue to be necessary to test hypotheses in vivo and in vitro to validate results.
Data & Services
There is a segment of companies that provide data, analysis, and other services to healthcare customers. These companies either provide a database that can be leveraged for research or diagnosis, such as DNA blueprints, or services, such as data management or sample collection.
Trial Process Improvement
Software and automation can streamline the clinical trial process by improving data collection, insights gathering, and matching. We have seen companies across the value chain, from automating data collection for contract research organizations (CROs) to improving matching between clinical trials and patients.
Synthesis & Production
These companies are synthesizing and/or producing DNA, microbes, or other organic compounds. Many use computational biology methods to leverage naturally occurring structures and processes to model how they can be reproduced or enhanced synthetically. The output can be used for research and drug development, among others.
All of this points to our central belief: the time is now for disruption across the healthcare value chain and marginal improvements are not enough to affect meaningful change. We need novel approaches that leverage the capabilities of machine learning. Machine learning will improve outcomes and reduce costs across the healthcare value chain by improving diagnoses, reducing errors, and streamlining the drug discovery process. The applications are wide and the potential for impact is exciting.
If you are working on an company in the computational biology space I’d love to hear from you. Reach me via email at medha@redpoint.com or on Twitter @mkhandel.